
Still think building a movie recommendation system demands weeks of setup? Rocket.new streamlines architecture, filtering strategies, and deployment, enabling collaborative, content-based, or hybrid models while addressing cold starts, sparsity, scaling, and performance control.
Too much setup for a movie recommender?
Not really. You still need solid logic, but you don’t need to rebuild the entire backend from scratch.
Traditional recommenders often take a long time because developers must collect and clean data, manage user ratings, write similarity calculations, and maintain server-side workflows.
Rocket.new speeds this up by providing a structured approach to building and deploying a production-ready recommender system while maintaining control over data, models, and performance.
You can implement collaborative filtering, content-based filtering, or a hybrid approach while handling data sparsity, cold start users, and scaling to thousands of users.
This blog covers architecture, filtering strategies, and deployment within a single workflow.
What is a Movie Recommendation System?
A movie recommendation system is a type of recommender system that predicts what movie a target user might enjoy based on user ratings, user behavior, and patterns found across users.
The system analyzes movie ratings, user preferences, and sometimes item features such as genre, actors, and release year. Then it applies collaborative filtering or content-based filtering to recommend movie titles that match the user's interests.
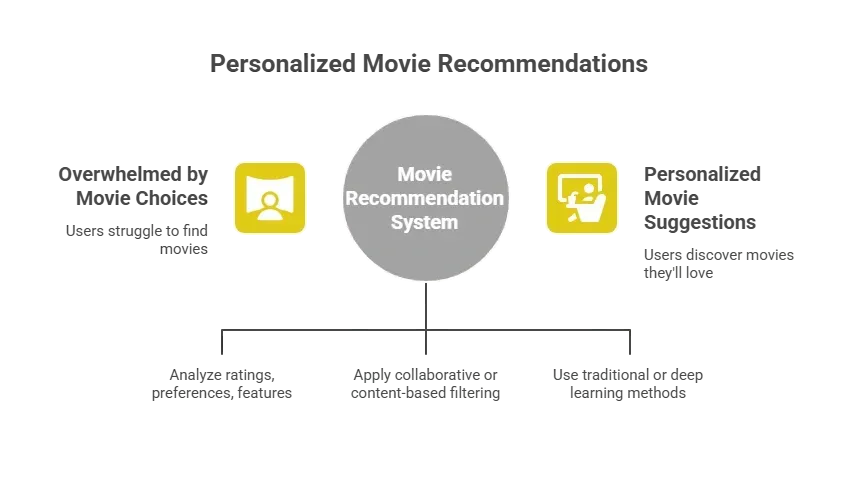
You can build this using traditional memory-based methods or model-based approaches, such as neural networks and deep learning.
Core Approaches in Recommendation Systems
Collaborative filtering predicts preferences by analyzing patterns among users. If two users have similar tastes, the system can recommend movie titles liked by one to the other.
Most recommendation systems fall into two categories:
- Collaborative filtering
- Content-based filtering
Both methods rely on data, but they use it differently.
Collaborative Filtering
Collaborative filtering predicts preferences by analyzing patterns among users. If two users have similar tastes, the system can recommend movie titles liked by one to the other.
For example:
- User A and User B rate several movies similarly.
- User A watches a new movie and rates it highly.
- The system suggests the movie to User B.
This method depends heavily on user ratings and the user-item matrix.
There are two main collaborative filtering systems:
- User based collaborative filtering
- Item based collaborative filtering
User-based collaborative filtering compares similar users. Item-based collaborative filtering compares similar movies.
Collaborative filtering algorithms often rely on cosine similarity and dot product calculations over user ratings.
Content-Based Filtering
Content-based filtering recommends movie titles based on item features. If a user likes action movies with strong female leads, the system analyzes that preference and suggests similar movies.
This method works well when user behavior is limited or when you have insufficient data from other users.
Content-based filtering depends on features such as genre, cast, and keywords. It does not depend on similar users. A hybrid system combining collaborative filtering and content-based filtering often performs best.
System Architecture with Rocket.new
Rocket.new also supports real-time updates. As users watch movies or rate them, the system can instantly update the user-item matrix and adjust recommendations. This ensures that the target user always sees suggestions that reflect their latest behavior.
Your movie recommender system will include:
- Frontend interface
- Backend API
- Database storing ratings and user data
- Machine learning model layer
You create your backend endpoints and database schema in Rocket.new. Then you connect your model for inference.
The system typically follows this structure:
- Users submit ratings and feedback.
- The system updates the user item matrix.
- The model computes similarity scores.
- The system returns personalized movie recommendation results.
With Rocket.new, building a movie recommendation system is fast and simple, letting you focus on delivering accurate, personalized suggestions.
Designing the User Item Matrix
The user item matrix is the foundation of collaborative filtering systems.
In this matrix:
- Each row represents one user.
- Each column represents one movie.
- Each value represents the user's rating.
For example:
| User | Movie A | Movie B | Movie C |
|---|---|---|---|
| U1 | 5 | 4 | ? |
| U2 | 5 | ? | 3 |
The missing values in the dataset. You calculate the similarity between two users by applying cosine similarity to their rating vectors.
The cosine similarity formula uses the dot product of rating vectors divided by their magnitudes. This allows the system to find similar users and recommend movie titles.
Handling Data Sparsity and Cold Start
Data sparsity happens when most users rate only a few movies. Large platforms face massive data sparsity because users interact with only a small fraction of the catalog.
To reduce this issue:
- Use content based filtering when ratings are sparse.
- Apply model based techniques using neural networks.
- Use average rating as a baseline for new users.
For new users without ratings, you can recommend top-rated movies based on the global average rating. For a specific user with a limited history, content-based methods are more effective.
Building Collaborative Filtering Step by Step
Collaborative filtering works best when you have user ratings and can identify patterns among similar users.
Let’s see how to build it step by step.
Step 1: Collect Ratings Data
Your system stores user ratings in the database.
Each rating includes:
- user_id
- movie_id
- rating value
This data feeds the user item matrix.
Step 2: Normalize Ratings
Subtract the average rating of each user from all the ratings. This helps handle bias from users who always give high ratings.
Step 3: Compute Similarity
Use cosine similarity to find similar users.
If two users have similar rating patterns, they likely share similar preferences.
Step 4: Predict Ratings
For a target user, calculate the predicted rating for unseen movies by averaging ratings from similar users, weighted by their similarity to the target user.
Step 5: Generate Recommendation List
Select movies with the highest predicted rating and return them to the given user.
Following these steps from collecting ratings to generating recommendations—creates a solid collaborative filtering pipeline.
With proper handling of missing values and normalization, the system can deliver reliable movie suggestions tailored to each target user.
User Based vs Item Based Collaborative Filtering
Collaborative filtering can focus on either users or movies. Choosing the right approach depends on your dataset and scalability needs.
- User Based Collaborative Filtering: The system compares ratings between users. If two users have similar rating patterns, movies liked by one user can be recommended to the other. This method focuses on finding similar users to predict preferences.
- Item Based Collaborative Filtering: Instead of comparing users, the system compares movies. If a user likes a movie, the system suggests other movies with similar rating patterns or features. Item based methods are more scalable for large datasets because the number of movies is usually smaller than the number of users.
At scale, collaborative filtering systems often combine memory based methods (like similarity calculations) with model based approaches (like matrix factorization or neural networks) to improve accuracy and handle data sparsity efficiently.
Model Based Methods and Deep Learning
Model based methods rely on machine learning techniques such as matrix factorization and neural networks.
Matrix factorization decomposes the user item matrix into lower-dimensional movie embeddings and user embeddings. Neural networks and deep learning can capture complex patterns in user behavior.
For example:
- Use embedding layers for movie and user vectors.
- Train with user ratings as labels.
- Predict rating for unseen movie titles.
Deep learning models can also combine content based features.
Large language models are now being used to interpret textual feedback and generate more effective movie recommendations.
Incorporating User Preferences and Feedback
User preferences evolve. The system must adapt to new data and recent user watches.
Track:
- Movies user watches
- Ratings
- Click behavior
- Watch time
Feedback can be explicit ratings or implicit signals. The model updates with new data periodically. This improves the reliability of recommendations and captures similar interests.
Example Walkthrough
Let’s consider an example.
User U enjoys action and thriller movies and consistently gives them high ratings. The system identifies two other users with similar tastes. Since these similar users rated a new thriller highly, the system predicts that User U will also enjoy it and recommends the movie.
Now, if User U occasionally watches romantic comedies, collaborative filtering alone may struggle due to limited ratings. Content-based filtering steps in by analyzing movie features like genre, actors, and keywords to suggest similar movies. Combining both methods in this hybrid approach yields more accurate, personalized recommendations.
Deploying the System with Rocket.new
Rocket.new allows you to quickly deploy a complete movie recommendation system. The typical steps include:
- Create backend routes: Set up API endpoints for ratings, feedback, and recommendations.
- Connect your database: Store user ratings, movie data, and user preferences.
- Deploy your model endpoint: Integrate your collaborative filtering or hybrid model for real-time predictions.
- Connect frontend: Display personalized movie recommendations to the target user.
Rocket.new makes it easy to prototype, test with sample data, and iterate to improve recommendation accuracy. Even without external tutorials, the platform’s built-in templates and documentation guide you step by step in creating a functional app and seamlessly connecting backend services.
Evaluation Metrics
Evaluating a movie recommendation system is crucial to ensure it delivers accurate and meaningful suggestions. Using the right metrics helps you understand both prediction quality and user satisfaction.
- RMSE for rating prediction
- Precision and recall for top N movie recommendation
- Coverage and diversity
Compare predicted ratings with actual ratings.
By tracking metrics such as RMSE, precision, recall, coverage, and diversity, you can assess how well your system predicts ratings and how well it meets user needs. Regular evaluation allows you to refine models, improve recommendations, and ensure your movie recommender system remains reliable and engaging.
Lessons from Building a Movie Recommendation System
Now you know how to build a movie recommender system using collaborative filtering, content based filtering, and model based machine learning techniques. You understand how the user item matrix works, how cosine similarity and dot product drive collaborative filtering, and how neural networks can improve predictions.
This approach also addresses common challenges like data sparsity and scaling. With Rocket.new, you can deploy the system quickly, test with real ratings data, and iterate without spending months on infrastructure. Start small with a single user and expand as you gather more feedback.
The biggest takeaway is that a recommender system is more than just suggesting movies. It learns user preferences, adapts to feedback, and delivers reliable, personalized recommendations over time, providing real value to both users and platforms.
Table of contents
- -What is a Movie Recommendation System?
- -Core Approaches in Recommendation Systems
- -Collaborative Filtering
- -Content-Based Filtering
- -System Architecture with Rocket.new
- -Designing the User Item Matrix
- -Handling Data Sparsity and Cold Start
- -Building Collaborative Filtering Step by Step
- -Step 1: Collect Ratings Data
- -Step 2: Normalize Ratings
- -Step 3: Compute Similarity
- -Step 4: Predict Ratings
- -Step 5: Generate Recommendation List
- -User Based vs Item Based Collaborative Filtering
- -Model Based Methods and Deep Learning
- -Incorporating User Preferences and Feedback
- -Example Walkthrough
- -Deploying the System with Rocket.new
- -Evaluation Metrics
- -Lessons from Building a Movie Recommendation System




