
AI query decomposition splits complex business questions into focused sub-queries, each retrieving its own evidence before synthesis. Rocket.new Solve applies this natively, producing structured research that ChatGPT and Perplexity cannot match on multi-dimensional questions.
Why does a chatbot confidently answer a multi-part business question while missing half of what was asked?
The problem is structural. Most conversational AI tools treat a user query as a single unit. They retrieve one batch of documents and the LLM generates one response.
For simple questions, that works fine. For complex ones with multiple angles, the result covers one dimension and skips the others entirely. A 2026 paper found that systems using structured reasoning trees for multi-hop questions outperform standard retrieval by 7.0% F1 and 6.0% EM, because splitting the original question into targeted components retrieves far more relevant documents per angle.
The process called AI query decomposition is what separates shallow AI research from genuinely useful output. Understanding that gap is what separates surface-level responses from research that drives real decisions.
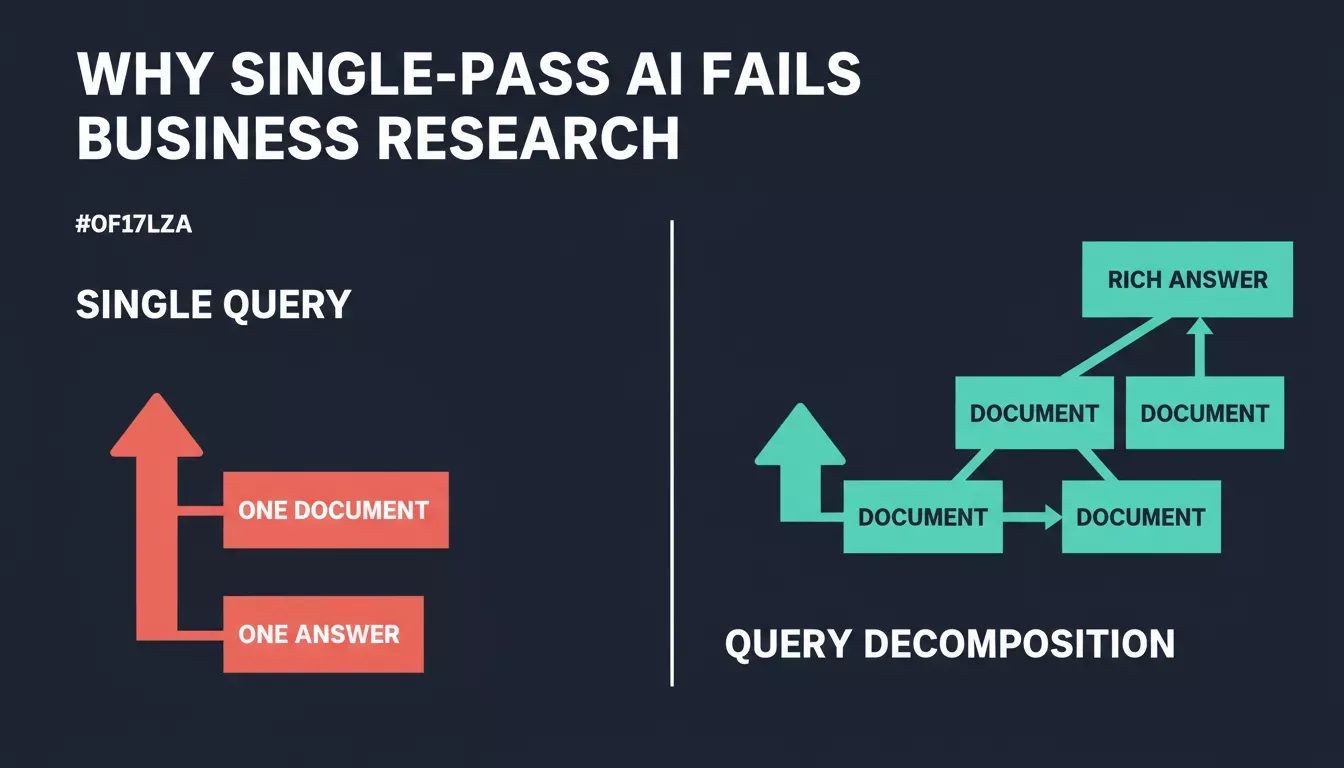
Single-pass retrieval answers one dimension. Query decomposition retrieves evidence for every dimension before synthesis.
Why Business Questions Resist Simple Answers
Most business questions are not actually one question. They carry three or four distinct sub-questions dressed up as a single user query.
When you ask "Which market should we enter next?" you are really asking about market size, competitive density, regulatory context, and operational readiness, four questions in one sentence. Each sub-question requires different sources, different documents, and a distinct reasoning path to answer correctly.
A single-pass retrieval system cannot split complex queries into their components. The LLM retrieves documents relevant to the surface phrase and answers from that one cluster, producing a response that can read as complete while skipping two of the four dimensions you actually needed addressed.
This is not a language model problem. It is a query processing problem: the system never broke the original query into manageable parts before retrieval began. When AI query decomposition does not happen, the retrieval system produces incomplete data and the final answer reflects incomplete context.
How Does AI Query Decomposition Work?
Query decomposition is a step that runs before retrieval. The system takes the original query and generates a set of smaller, focused sub-questions, each of which can be answered independently.
Each sub-question targets a specific document category, data type, or reasoning path. The decomposed queries are dispatched to the retrieval system in parallel or in sequence, with each sub-query pulling its own set of relevant documents.
A sub-question query engine generates these sub-questions automatically, runs retrieval on each, and synthesizes the results into a single final answer using the LLM.
The key mechanism: each sub-query is self-contained and can be answered independently. Some systems also use hypothetical document embeddings (HyDE), where the LLM generates a hypothetical document resembling the ideal answer, then retrieves real documents closest to that hypothetical in the knowledge base. This closes semantic gaps that standard keyword search cannot close.
AI query decomposition: one business question splits into targeted sub-queries, each retrieving its own evidence before synthesis.
Parallel vs. Sequential Execution
Once query decomposition has split the original question, the sub-queries can run in different patterns that shape the depth and coherence of the final answer.
Parallel execution fires all sub-queries at once, fast and effective when sub-queries do not depend on each other's results.
Sequential execution processes sub-queries step by step, using the result of one to inform the next, which is better for multi-hop questions where the answer to sub-query 1 determines what sub-query 2 should search for.
Most production retrieval systems use a mix: a planning step maps the dependencies, then parallel retrieval runs where it can. Most compound strategy questions benefit from at least partial sequential decomposition.
The Research Behind the Performance Gap
The performance advantage of AI query decomposition over single-pass retrieval is not theoretical. A 2026 paper, "Reasoning in Trees: Improving Retrieval-Augmented Generation for Multi-Hop Question Answering" (RT-RAG), accepted at WWW 2026, reports that RT-RAG substantially outperforms existing methods by 7.0% F1 and 6.0% EM on multi-hop QA benchmarks.
The benchmark measures performance on multi-hop question-answering datasets. The underlying mechanism, structured reasoning trees that decompose a compound question into components, is identical to what query decomposition-based research tools apply to business questions.
Most compound business questions are structurally multi-hop. Market entry, competitive assessment, and pricing strategy each require evidence from different source types to answer different sub-questions before synthesis. A system that handles that structure explicitly produces better output than one that does not.

Structured reasoning trees outperform standard single-pass retrieval on multi-hop QA benchmarks. The same decomposition mechanism applies to compound business research.
What Makes a Sub-Question Engine Different from a Chatbot?
A conversational AI generates answers from a flat context window. A sub-question engine is architecturally different, and the distinction shows up most clearly in how each handles questions with multiple dimensions.
A chatbot treats every user question as a prompt. The LLM uses its internal knowledge or a single retrieval call to generate a response, one shot, one output. A sub-question engine first models the question structure, identifying how many distinct parts the question contains, what each sub-question needs as input, and whether any are dependent on each other.
This matters for business research because the questions worth researching are compound. "Should we acquire this company?" or "Which pricing model fits our market?" each have multiple dimensions that a single retrieval pass cannot fill.
Chatbot answers are fluent; sub-question engine answers are sourced, segmented, and grounded in retrieved documents. When AI query decomposition is built into the architecture, the difference in output quality is significant and measurable.
"The stat that stood out: 60 to 70 percent of people using vibe coding tools don't know what they're actually building. That's a missing product category." - LinkedIn
Understanding question dimensions before research begins is what separates surface-level LLM responses from research that drives real decisions. Rocket.new Solve is built on this principle, its six-step research pipeline runs query decomposition at step four, before a single retrieval agent is dispatched.
RAG and Document Retrieval: The Engine Behind the Research
The engine behind any sub-question query system is retrieval-augmented generation (RAG). RAG connects a large language model to an external knowledge base or dataset, rather than relying solely on training data, and each sub-query benefits from this connection independently.
When a sub-query is dispatched, the retrieval system searches for documents most semantically relevant to that specific question, pulls the top results, and passes them as context to the LLM. The quality of the final answer depends entirely on what gets retrieved; poorly targeted retrieval produces vague responses; per-sub-question retrieval produces grounded, cited answers.
Some RAG pipelines use HyDE, generating a synthetic representation resembling the ideal answer and then retrieving real documents closest to that representation in embedding space.
The LangChain RAG documentation covers this pipeline in detail, it is what enables a research system to pull from live sources and PDFs rather than being limited to what was frozen into the LLM at training time.
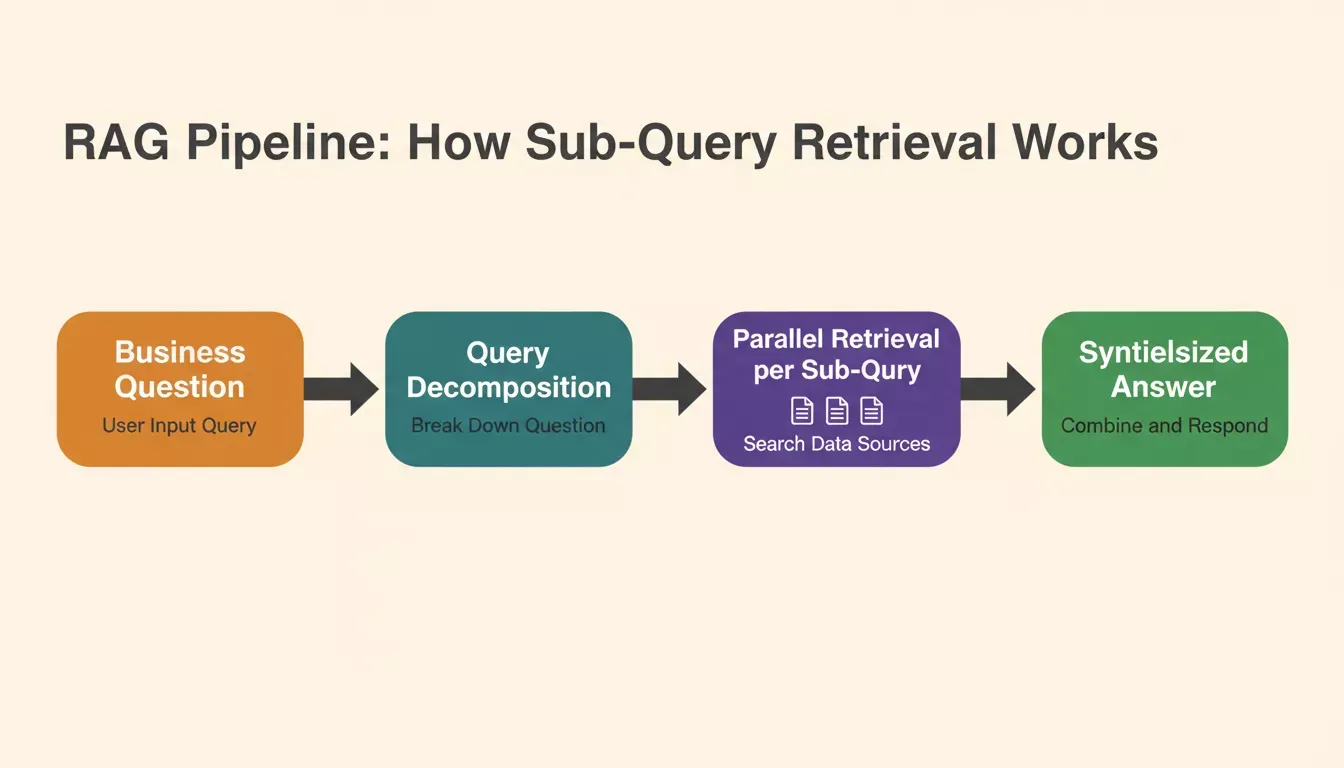
The RAG pipeline: each sub-query retrieves its own document set independently before the synthesis layer combines all contexts into a final answer.
Where ChatGPT and Perplexity Fall Short on Business Research
Both ChatGPT and Perplexity are useful tools. For structured business research on complex questions, their architecture creates a ceiling.
ChatGPT's base model pulls from training data with a static knowledge cutoff; its responses reflect what the LLM learned during training, not live documents or current market datasets.
A web browsing add-on is available, but even with it, ChatGPT treats the query as a single search string with no decomposition step. Perplexity runs real-time web searches and cites sources, which is genuinely useful for current events, but it also treats the user query as a single search string and does not split complex requests into sub-questions before retrieval begins.
Neither system has a native AI query decomposition step. Both generate a response from whatever the first retrieval pass found, which works for simple questions and fails for compound ones. Multi-dimensional business questions lose their additional context the moment they are handled as a single input.
When ChatGPT or Perplexity Is the Right Call
For quick factual lookups, current events, or exploratory brainstorming, ChatGPT and Perplexity are faster and require no setup. The case for AI query decomposition only becomes compelling when the question has multiple dimensions that each require different evidence.
For simple queries, the added step of decomposition adds no benefit; the right tool is the one that answers fastest.
Rocket.new Solve is the only general-purpose business research tool with a native query decomposition step. ChatGPT and Perplexity are designed for speed on simple questions, not depth on compound ones.
Rocket Solve vs. ChatGPT vs. Perplexity: Feature Comparison
| Feature | ChatGPT | Perplexity | Rocket.new Solve |
|---|---|---|---|
| Query handling | Single-pass generation | Single search + cite | Multi-step decomposition |
| Sub-question depth | None | None | Full sub-question engine |
| Document retrieval | Training data (static) | Live web search (single-pass) | Targeted per sub-query |
| Structured output | Prose only | Prose + citations | Structured research deliverable |
| Decomposition architecture | None | None | Native mechanism |
| Live data sources | Optional (web browsing add-on) | Yes (web search, single-pass) | Yes (connected sources, per sub-query) |
| Output format | Paragraph answer | Paragraph + source list | Executive summary, analysis, evidence, recommendations |
| Follow-up depth | Limited memory | New search | Builds on full project context |
The absence of a query decomposition step is not a flaw in these tools. It is a design choice for a different use case. For business research that needs to answer four questions at once, that choice becomes the limitation.
How Rocket Solve Applies AI Query Decomposition
Rocket Solve takes a business question, decomposes it into its component dimensions, runs targeted retrieval against each one in parallel, and synthesizes the findings into structured research output.
The system doesn't treat your question as a search string. Each decomposed dimension runs as a separate agent stream with its own retrieval, tools, and reasoning path. Nothing gets collapsed into a single pass, so the final answer reflects every dimension of what was asked, not just the most visible one.
That output doesn't reset after export. It becomes the foundation for everything that follows in the project: the PRD is present when the developer opens the build task; the competitive brief is present when the landing page is written. This is the cross-task context architecture that makes Rocket a platform rather than a one-shot research tool.
Solve connects to live sources, so retrieval isn't constrained to a training snapshot. When you need to validate a business idea against current market data, the system pulls from the right sources at the right time. Results export as structured reports, PDFs, or shareable PPTX decks; no reformatting required.
What Does This Look Like in Practice?
The process is cleaner than it sounds. Here is what happens when a team runs a complex business question through a query decomposition-based research system.
-
Step 1: You press Enter on a question like "What should our Series A pricing strategy look like given the current competitive environment?"
-
Step 2: The system maps the question's dimensions: what competitors charge, what customers in similar categories pay for, what your unit economics allow, and how positioning affects perceived value.
-
Step 3: Sub-queries are generated for each dimension. You can watch them appear in chat as research begins, each one a focused search string, not a paraphrase of your original question.
-
Step 4: Retrieval runs against each sub-query in parallel. Documents are pulled per angle and returned with source context.
-
Step 5: The synthesis layer combines all results and generates a structured answer with sections, not a single block of prose.
-
Step 6: You click through the cited sources, check the evidence, and use the output directly in a decision memo or board presentation.
This is AI query decomposition in action. The first time you see a complex question fully answered across all its dimensions at once, single-pass search starts to feel inadequate by comparison. For teams running competitive teardowns or market analysis, this structured output is the difference between a research session and a decision-ready deliverable.
The Verdict
Research quality depends on how a question is handled before the LLM ever processes it. Decomposing a complex query into focused parts, retrieving documents per angle, and synthesizing across all of them produces fundamentally better output than a single-pass search.
The RT-RAG paper demonstrates this on benchmark datasets, and it's the same mechanism Rocket Solve applies to business research. The teams getting the sharpest insights aren't just asking better questions; they're using systems built to break questions down and cover every dimension.
For quick lookups and current events, ChatGPT and Perplexity are the right tools. For compound business questions where missing one dimension means making the wrong call, query decomposition isn't optional; it's the architectural requirement.
Rocket Solve is the only general-purpose business research tool that applies it natively. Submit your hardest business question and see what a decomposition-first engine returns at Rocket.new.
Table of contents
- -Why Business Questions Resist Simple Answers
- -How Does AI Query Decomposition Work?
- -Parallel vs. Sequential Execution
- -The Research Behind the Performance Gap
- -What Makes a Sub-Question Engine Different from a Chatbot?
- -RAG and Document Retrieval: The Engine Behind the Research
- -Where ChatGPT and Perplexity Fall Short on Business Research
- -When ChatGPT or Perplexity Is the Right Call
- -Rocket Solve vs. ChatGPT vs. Perplexity: Feature Comparison
- -How Rocket Solve Applies AI Query Decomposition
- -What Does This Look Like in Practice?
- -The Verdict




